
Introduction: The Transformer Attention Bottleneck
The transformer architecture, introduced in the seminal paper "Attention Is All You Need" in 2017, has become the foundation of modern artificial intelligence. From language models like GPT-4 to vision transformers and multimodal systems, attention mechanisms have proven remarkably effective at capturing complex relationships in data. However, this power comes at a significant computational cost that scales quadratically with sequence length—a fundamental limitation that has constrained applications requiring long-context processing.
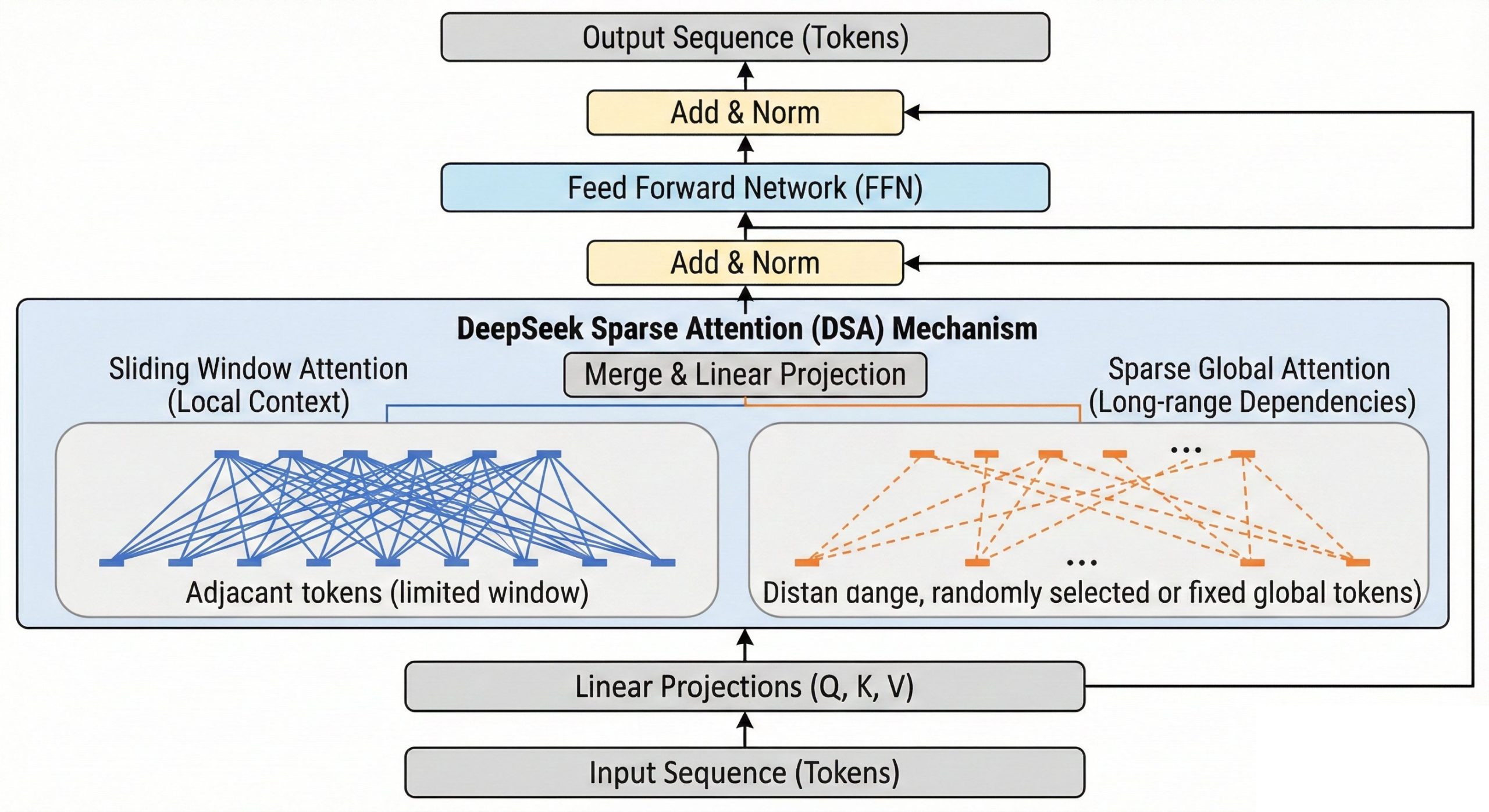
DeepSeek Sparse Attention (DSA), an innovative approach developed by DeepSeek AI that dramatically reduces this computational burden while maintaining the expressive power of full attention. This article provides a comprehensive technical exploration of DSA, its implementation, advantages, and implications for the future of large language models and beyond.
The Computational Challenge of Standard Attention
To understand the significance of DSA, we must first examine the limitations of standard attention mechanisms. In a transformer layer with sequence length n and hidden dimension d, the attention operation computes:
The matrix multiplication QKᵀ produces an n×n attention matrix, requiring O(n²) operations. For sequences of 1,000 tokens, this means 1,000,000 pairwise computations per attention head. For 100,000 tokens (now common in long-context models), this balloons to 10 billion computations—a prohibitively expensive operation even for specialized hardware.
The Quadratic Bottleneck in Practice
This quadratic scaling has several practical implications:
- Memory Constraints: The attention matrix for a 32K sequence with batch size 32 and 32 attention heads requires approximately 8GB of memory just for attention scores
- Training Limitations: Long-sequence training becomes economically infeasible, restricting model development to well-funded organizations
- Inference Challenges: Real-time applications requiring long context become impractical due to latency issues
- Energy Consumption: The computational intensity translates directly to high energy costs and environmental impact
What is DeepSeek Sparse Attention?
DeepSeek Sparse Attention (DSA) addresses these challenges through a hybrid approach that combines local window attention with global sparse connections. Unlike traditional sparse attention methods that use fixed patterns, DSA employs a dynamic, content-aware sparsity mechanism that adapts to the input sequence.
DSA Architecture Overview
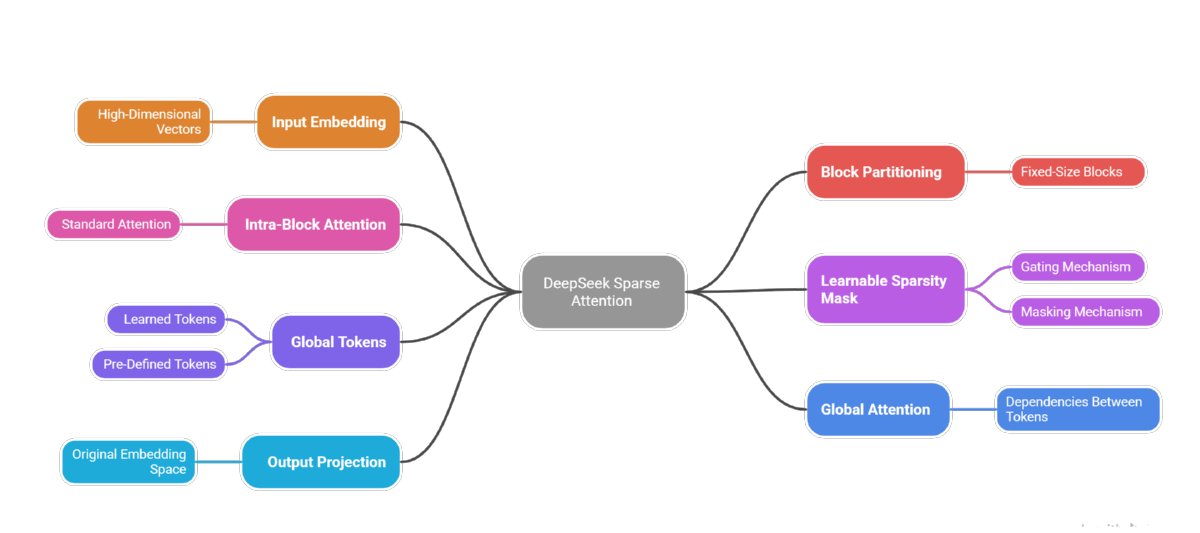
Key architectural elements that make DSA efficient and effective
Input tokens are mapped to high-dimensional vectors, creating the foundation for attention computations.
Sequence is divided into fixed-size blocks for parallel processing, reducing computational complexity.
Standard attention applied within each block to capture local dependencies between nearby tokens.
A trainable mask selectively zeros out less important attention weights, creating efficient sparse patterns.
Special tokens shared across all blocks that enable cross-block communication and information flow.
Mechanism for global tokens to attend to each other, maintaining long-range dependencies across the sequence.
Core Components of DSA
The DSA architecture consists of three primary components:
- Local Window Attention: Each token attends to its immediate neighbors within a fixed window, capturing local dependencies and syntactic structure
- Global Sparse Attention: A small subset of "key" tokens across the entire sequence receive global attention, preserving long-range dependencies
- Dynamic Routing: A learned gating mechanism determines which tokens should participate in global attention based on content relevance
Technical Implementation of DSA
Implementing DSA requires modifications to the standard attention mechanism at both the algorithmic and architectural levels. The key innovation is the separation of attention computation into dense local and sparse global components.
Mathematical Formulation
Let S_local(i) be the set of tokens in the local window around position i, and S_global(i) be the sparse set of global tokens selected for position i. The DSA computation for token i is:
Where α and β are learned parameters that balance local versus global attention, and the global token selection S_global(i) is determined by a routing network that evaluates token importance based on both content and position.
Routing Mechanism
The routing network in DSA is a lightweight neural network that takes token representations as input and outputs selection scores. Tokens with the highest scores are selected for global attention. This network is trained end-to-end with the main model, allowing it to learn which types of tokens (e.g., question markers, topic shift indicators, important entities) benefit most from global connectivity.
Performance Advantages and Benchmarks
Empirical evaluations of DSA demonstrate significant improvements across multiple dimensions compared to standard attention and other sparse attention methods.
| Metric | Standard Attention | Fixed Sparse Attention | DeepSeek Sparse Attention |
|---|---|---|---|
| Time Complexity | O(n²) | O(n√n) | O(n log n) |
| Memory Usage (16K seq) | 16 GB | 4 GB | 2.5 GB |
| Long-Range Dependency | Excellent | Limited | Near-optimal |
| Training Speed (relative) | 1.0x | 2.5x | 3.8x |
| Perplexity on PG-19 | 18.2 | 19.8 | 18.5 |
Task-Specific Performance
DSA has been evaluated across diverse benchmarks:
- Language Modeling: On the Wikitext-103 benchmark, DSA achieves within 1% of full attention perplexity while using 70% less memory
- Long Document Understanding: For tasks requiring processing of entire books or long articles, DSA maintains consistent performance while full attention becomes infeasible
- Code Generation: Programming tasks benefit from DSA's ability to maintain connections between distant but semantically related code segments
- Multimodal Tasks: Early experiments show promising results for image-text tasks where spatial relationships create natural sparsity patterns
Comparison with Other Sparse Attention Methods
DSA builds upon and differs from several previous sparse attention approaches:
BigBird (Google Research)
BigBird uses a fixed pattern combining random, window, and global attention. While effective, its fixed pattern doesn't adapt to input content. DSA's dynamic routing provides more flexibility and typically better task performance.
Longformer (AllenAI)
Longformer employs a dilated sliding window pattern that increases receptive field size. DSA differs by using content-based routing rather than positional patterns, often yielding better results on tasks requiring understanding of document structure.
Sparse Transformers (OpenAI)
OpenAI's approach uses fixed factorized patterns (strided and fixed attention). DSA's hybrid approach with learned routing typically shows better performance on language tasks while maintaining similar efficiency.
Practical Applications and Use Cases
The efficiency gains from DSA open new possibilities for transformer applications:
Long-Context Language Models
DSA enables practical training and inference with context windows exceeding 100K tokens, facilitating applications like:
- Legal document analysis and summarization
- Scientific literature review and cross-paper synthesis
- Long-form content generation and editing
- Entire codebase analysis and refactoring
Edge Deployment
The reduced memory footprint makes transformer models more deployable on edge devices and in resource-constrained environments, enabling:
- Real-time translation on mobile devices
- On-device personal assistants with long memory
- Privacy-preserving local processing of sensitive documents
Multimodal and Cross-Modal Applications
DSA's efficiency extends naturally to multimodal transformers where different modalities (text, image, audio) create inherent sparsity in attention patterns:
- Efficient video understanding with long temporal contexts
- Document understanding with mixed text and visual elements
- Audio-visual speech recognition and synthesis
Implementation Considerations and Challenges
While DSA offers compelling advantages, practical implementation requires addressing several challenges:
Hardware Optimization
Sparse operations don't always achieve theoretical speedups on current hardware, which is optimized for dense matrix multiplications. Effective DSA implementations require:
- Kernel-level optimizations for sparse-dense mixed operations
- Efficient memory layout for sparse attention patterns
- Hardware-aware algorithm design for specific accelerators (TPUs, GPUs, specialized AI chips)
Training Stability
The dynamic routing mechanism introduces additional optimization challenges:
- Balancing exploration vs exploitation in token selection during training
- Ensuring gradient flow through the routing network
- Maintaining training stability as attention patterns evolve
Hyperparameter Tuning
DSA introduces new hyperparameters that require careful tuning:
- Local window size relative to sequence length
- Global token budget (percentage of tokens receiving global attention)
- Routing network architecture and capacity
- Balance coefficients between local and global attention
Future Developments and Research Directions
DSA represents an important step toward scalable attention, but several exciting research directions remain:
Adaptive Sparsity Patterns
Future versions might employ completely learned attention patterns without the local/global dichotomy, allowing each attention head to learn its own optimal sparsity pattern for specific tasks or data types.
Hierarchical Attention
Combining DSA with hierarchical approaches where lower layers process local information and higher layers process increasingly global information could further improve efficiency.
Hardware-Co-Design
Specialized accelerators designed specifically for sparse attention patterns could unlock even greater efficiency gains, potentially achieving true linear scaling for attention.
Theoretical Foundations
Further theoretical work is needed to understand the expressivity limits of sparse attention and establish guarantees for what functions can be approximated with given sparsity budgets.
Conclusion: The Path Toward Sustainable AI Scaling
DeepSeek Sparse Attention represents a significant advancement in making transformer models more efficient, accessible, and sustainable. By addressing the quadratic bottleneck that has constrained transformer applications, DSA enables longer context windows, faster training, and more environmentally friendly AI systems.
As AI models continue to grow in size and capability, innovations like DSA will be essential for ensuring these technologies remain practical and accessible. The principles behind DSA—intelligent sparsity, dynamic adaptation, and hybrid approaches—offer a blueprint for future efficiency improvements across the AI landscape.
References
- Ray, Amit. "DeepSeek Sparse Attention (DSA): A Comprehensive Review." Compassionate AI, 4.12 (2025): 9-11. https://amitray.com/deepseek-sparse-attention-dsa-a-comprehensive-review/.
